
Supercharging data quality with a common platform for data analysts and engineers
“File a request and we’ll try to prioritize it for next quarter” is the polite way of saying you’re probably not getting support anytime soon. In organizations that generate large volumes of data, data engineering teams are usually stretched too thin to maintain every single table. Furthermore, they may not have the context to fully understand every piece of data in the platform.
Data organizations have a need to scale data quality from being one team’s responsibility to being the responsibility of those with the most information about that data. Sharing responsibility with the teams that have the most context in how that data is used by the business and how that data is created moves us towards our goal of democratizing data quality.
At Included Health, data is integral to our mission of raising the standard of care for everyone. We have a variety of datasets documenting details about all patient interactions with our products, and stakeholders from across the company use this data to inform decisions. In this post, we’ll share how we leveraged Anomalo to transition from fragmented data engineering and data analytics to democratized data quality initiatives.
Data health used to be opaque to our analysts
Included Health’s data engineers are responsible for building and maintaining the company’s data platform while data analysts rely on this infrastructure for generating insights. Data quality is therefore relevant to both roles, but historically, analysts had less agency to address this issue.
Data analysts primarily operate in DataHub and Querybook, open-source tools designed with the analytics use case in mind. These tools enable analysts to understand data lineages, annotate data, and ultimately query data to generate insights. Their user-friendly interfaces and advanced visualization features make them well suited to the analytics team’s needs.
That said, DataHub and Querybook are fundamentally a data usability platform. While they do shed some light on data observability (i.e. whether pipelines are working as intended), they don’t shed light on data quality (i.e. why a pipeline is not working as expected). Data quality matters because even when pipelines are healthy, the data values themselves may have changed, such as through a distributional shift or an uptick in NULLs. For the most part, our analysts used to have to sniff out unreliable data according to their own intuition; they didn’t have the tooling to proactively look for data quality issues, much less to resolve them.
Data engineers, on the other hand, regularly use a dedicated in-house data observability tool called Houston. Because of engineers’ greater visibility into data pipelines, and their technical knowledge about the overall infrastructure, analysts would come to them for support. We have a Slack channel dedicated to cross-team analytics where conversations used to go like this:
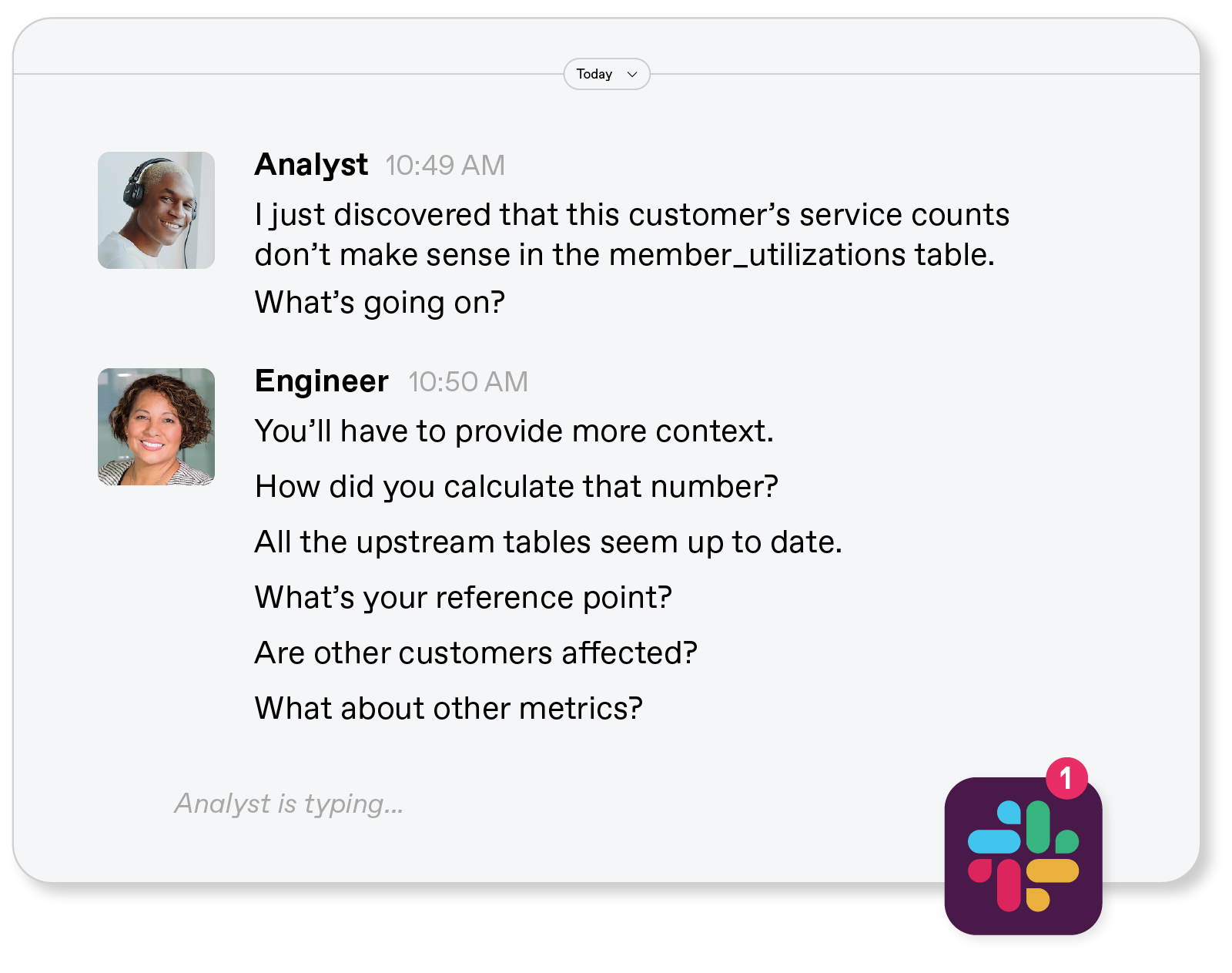
Clearly, this isn’t productive, especially when multiplied by all the potential data quality issues that come with data at our scale. With substantially fewer people than the analytics team, our data engineering team certainly has a lot on its plate. Naturally, the engineering team prioritizes the datasets they own over custom datasets the analytics team has built on top of the engineering team’s infrastructure.
When a data quality issue pops up in one of the analytics team’s custom tables, the engineering team doesn’t know what to do with it. These tables don’t have SLAs, active testing, or incident response plans, and they don’t page out when someone finds something is broken. Instead, analysts must organically discover the issue and then try to partner with data engineering to get it fixed. The ensuing back and forth to precisely define the issue further contributes to the slowdown.
Anomalo bridges the gap between data engineering and analytics
Introduce Anomalo, the data quality platform that acts as a single source of truth across both data teams and the broader Included Health organization.
Anomalo has transformed Included Health’s data incident response pipeline so we’re no longer searching for a needle in a haystack. Before, data analysts weren’t empowered to monitor their own data’s quality, and when they stumbled upon data that seemed wrong, it was incredibly difficult to get more context. Now, data analysts can use Anomalo to monitor their own tables and reduce the number of requests to the data engineering team. Anomalo’s unsupervised machine learning algorithms detect abnormal data and predict the most likely cause, which analysts can either debug directly or escalate to data engineering as needed.
Anomalo brings with it a number of unique advantages:
- Data quality in addition to data observability: Anomalo actually monitors the contents of our data, not just whether it’s arriving on schedule.
- Accessible to both technical and non-technical users: Users can take their pick between either a convenient no-code/low-code GUI and a full-fledged CLI and API.
- Bounded complexity: Machine learning algorithms enable root cause detection, making it easier to define the scope of a problem and troubleshoot it.
Anomalo has played a vital role in unifying engineers and analysts to take joint ownership over data quality. Thanks to Anomalo, our Slack conversations are a lot more succinct and actionable:
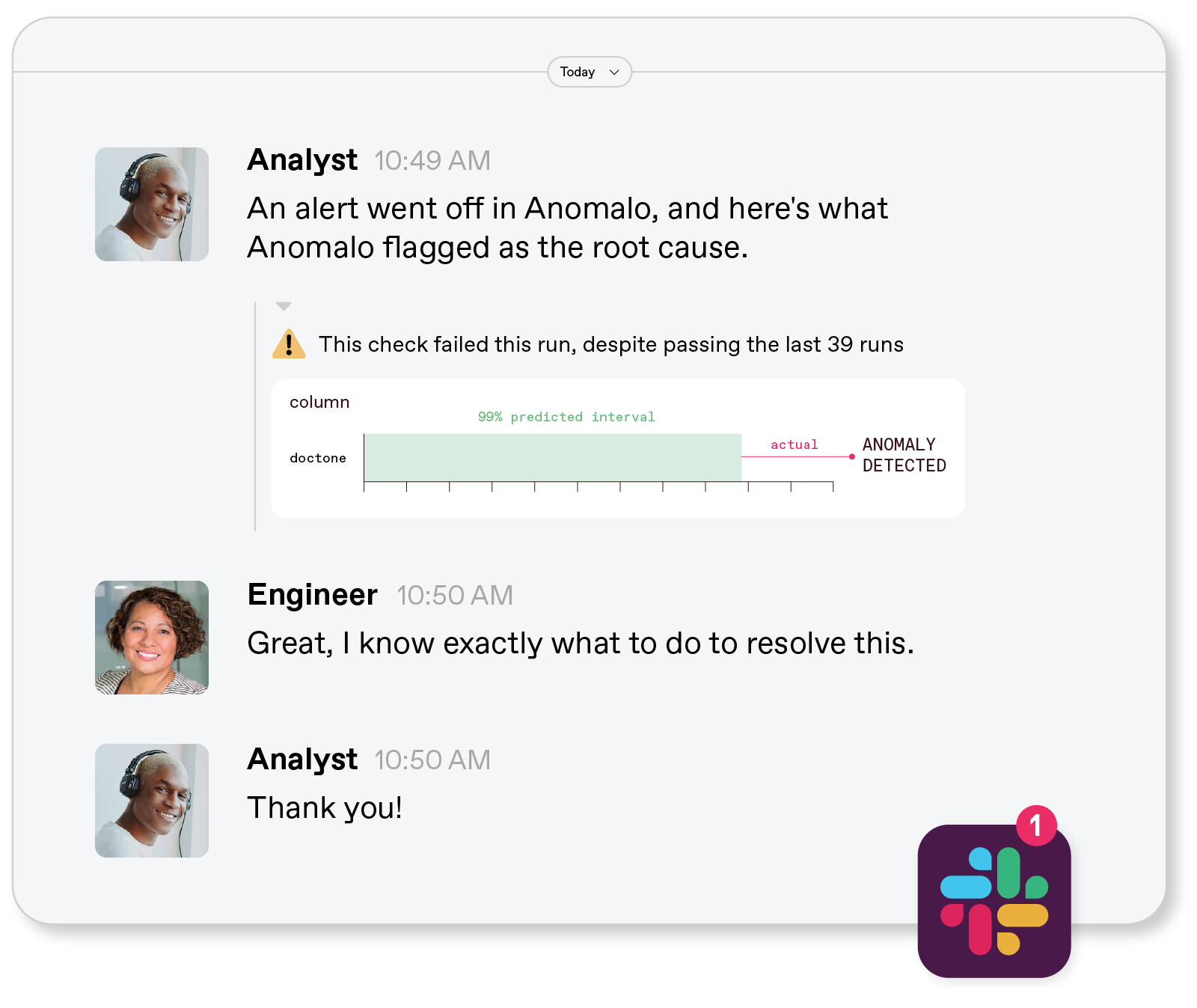
Anomalo’s alerting also plays a part in distributing data quality ownership across the organization. Remember all those tables that data engineering didn’t have the resources to cover? Data professionals have been able to take monitoring into their own hands thanks to Anomalo’s Slack alerts. Team members also appreciate UI features that allow the fine-tuning of alerting thresholds and management of noise. Anybody, not just engineers, can update Anomalo’s SQL checks, which has reduced the barrier to entry for owning data quality.
Elevating data governance with Anomalo
With Anomalo, we’ve made a significant leap in our data governance standards with the establishment of alerting for 791 datasets and counting. Whereas we were previously limited by the size of our data engineering team, Anomalo has made data quality accessible to our analytics team, too. Data engineers can concentrate on their core work and get involved in data incident resolution after analysts have used Anomalo to identify an issue’s root cause. It’s been a cultural shift—data quality issues feel tractable now and something for which everybody can do their part.
Data governance is an ongoing effort at Included Health, and tools like Anomalo help us in managing this space so we can focus on raising the standard of care for members.
If you are interested in raising the standard of care with data, reach out to us at Included Health or visit our careers page. We’re hiring! To learn more data quality monitoring and alerting, you can request a demo of Anomalo for your own company today.


